How Procurement Can Become Data Driven: Collect More Data

Many procurement organizations face a dilemma: They dream about an emerging future in which analytics, artificial intelligence, bots, and other technologies work in tandem to automate and accelerate work while improving procurement outcomes. But the dream ends abruptly when it becomes clear they lack the right data and enough data needed for this future promise to become reality.
For instance, typical procurement organizations only gather transaction information and, maybe, line-item data. They’re missing the contextual information surrounding purchasing decisions—especially the process data related to the steps they take to, for instance, review and approve a requisition, set up a contract, or go through an RFP. In some cases, they may even have very little transaction data in a particular spend category. Perhaps most importantly, they also aren’t tapping into the vast range of critical third-party and other external data.
All this data is critical to building knowledge models that make analytics and AI work. With robust knowledge models, AI can learn the language of procurement and the business—and, in turn, help procurement improve its speed, agility, and efficiency; give decision makers better visibility; reduce risk; and boost compliance.
Data is the currency of the future—it underpins every decision a company could make when predicting people’s needs, determining which goods or services are available to best meet those needs, selecting the right suppliers, and knowing the right price to pay. And that’s why it’s time for procurement to begin taking the steps necessary to become a data-driven organization.
Recognizing the Data Dilemma
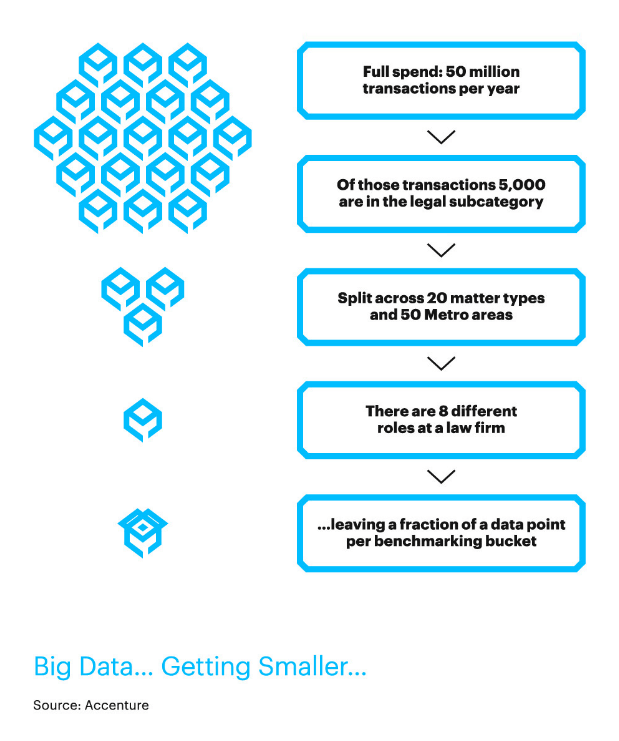
A hypothetical example shows how the lack of data can stymie a company’s efforts to produce the optimal business outcome. Meet Universal Manufacturing, which finds itself in a bind because its “big” data has suddenly become very small (Figure 1).
Universal wants to know what it should be paying for legal services—more specifically, how much a certain type of legal expertise in a particular market should cost. But there’s a time crunch: The company needs to retain an attorney within a week or two, so it doesn’t have the luxury of engaging procurement in a comprehensive legal labor rate benchmarking exercise.
With about 50 million transactions a year related to indirect spend, Universal has a lot of data in general. But only about 5,000 of those transactions are for legal services. And those transactions are split across 20 areas of expertise (i.e., subject matter types, such as real estate law or contract law), 50 metro areas, and eight different roles within the law firms the company works with (i.e., senior partner or associate). This means Universal really has only a fraction of the data that’s relevant to what it wants to buy today—effectively worthless from a comparative standpoint. For example, Universal may know how much it pays a contract law partner at a firm in Philadelphia. But that can’t shed any light on what it should pay a real estate junior associate in Kansas City.
Figure 1: Universal Manufacturing’s Data Dilemma
Solving the Data Dilemma
What does a company need to solve a data dilemma like the one Universal faced? First, it has to have an intentional strategy to find and capture the right data.
Simply going out and collecting more and more data could help address the data deficiency a typical procurement organization struggles with. But more data won’t by itself necessarily result in better procurement performance. For that, a company should have an explicit understanding of:
- which problems it wants to solve
- the data needed to build the knowledge models that analytics and AI need to solve the problems
- the extent to which the company has that data already
- the additional data needed and where it resides
In Universal’s case, the company already had a lot of transaction data, and could have collected much more data beyond that. But without first identifying the specific need—knowing what to pay a real estate junior associate in Kansas City—it probably wouldn’t have gotten the right answer. In other words, if Universal had solved its problem with the wrong data, it would have been a worthless exercise.
Building Knowledge Models
In addition to a defined data strategy, a company should have knowledge models so analytics and AI can effectively use the data collected.
Knowledge models create relationships among data, similar to the way people think. That’s crucial to AI’s ability to process and generate insights from data in a way that mimics how humans do it. And to use AI comprehensively, a company needs to create a knowledge model for each procurement subcategory. This could number in the hundreds for the typical organization.
Say you have a single supplier that services a number of geographies and sells a certain number of items, each of which for a certain price. A knowledge model, paired with a reasoning engine, enables AI to understand and answer the natural language question, “Which suppliers sell steel tubes in China, and how much do they cost?”
You can expand on that basic model to create more complex and probabilistic relationships among data to deepen the insights you get. Such relationships enable AI to discern that if a supplier sells, for instance, steel tubes, there’s an 85 percent chance it also sells rolled steel. As a result, you can add qualified new suppliers to the list of companies you should include in your future RFPs.
In short, knowledge models are vital to turning a vast collection of data into useful insights that benefit the business. And they, as well as data capture activities and correlations, must be continually evolved to avoid becoming outdated as the business changes.
When a data strategy is teamed with knowledge models, the result resembles what’s in Figure 2, which illustrates the route Universal took to get the data—and the AI-enabled insights—it needed.
Figure 2: Universal’s Solution to its Dilemma
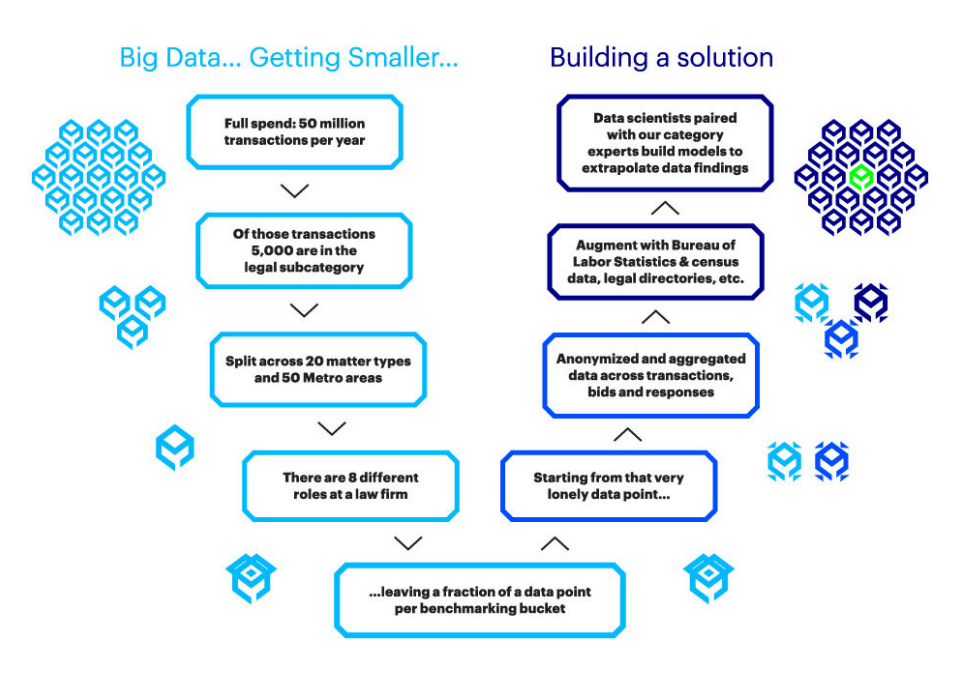
In this case, the company used an Accenture-built predictive model that aggregated Universal’s own limited data with related, anonymized legal labor data—across transactions, bids, and responses—from hundreds of other companies that also purchase legal services.
It augmented this data with other relevant data from external sources, such as legal directories, the Bureau of Labor Statistics, and the Census Bureau. Data scientists and category experts—in this case, those with extensive experience in purchasing legal services—then built AI models to extrapolate the insights from the data and give Universal what it ultimately was looking for: how much it should pay for a real estate junior associate in Kansas City.
The Future of Procurement: From Process Driven to Data Driven
Today, every procurement activity—whether it involves sourcing, contracting, or making purchase transactions—is tied to rigid manual or digital process workflows. But being highly process driven stifles efficiency, often undermines compliance, and prevents a company from developing the kinds of insights it needs to make better decisions.
As procurement becomes more data driven, processes don’t go away. Instead, those processes become much more fluid. A person could, for example, skip several steps in a process if he had the right data and insights. Compliance and controls are inherent and embedded in the knowledge models so users simply see valuable information presented that they can act on. The “process” effectively moves into the background, replaced by the right data going to the right people at the right time. And the results are better decisions, greater compliance, and a more efficient procurement organization.
The future of procurement is, indeed, data driven. And the sooner procurement organizations can begin capturing that data, the sooner they can put it to work to solve their most pressing problems.
