TableNet: A Smart and Automated System to Extract Tables From Invoices

The artificial intelligence (AI) teams at Coupa often need to apply the latest technology in creative ways to solve problems for our customers. One example of this is reading invoices with our InvoiceSmash product.
Automatically reading invoices from PDFs was always a specialized task. Invoices have many different dates on them, and it is important to understand all of these. Within the invoice, you need to figure out what is the header (with all its information) and find the table with all the line items.
Reading that table (also called table extraction) is especially difficult.
Many existing solutions for table extraction mainly concentrate on building rule-based algorithms and systems. These solutions are inflexible, and often suffer from poor generalization in parsing varying table structures from different invoice templates.
AI-based systems using deep learning algorithms have become a promising alternative to the rule-based systems due to their ability to learn and generalize. These are the same algorithms used in image recognition, natural language processing, and translation.
However, when it comes to table extraction, much of the work exists as academic research; there is a scarcity of production-ready table extraction systems that can provide reliable and accurate extraction. This blog introduces “TableNet” — a production-ready and deep-learning-based table extraction system for invoices.
For many document types, it may be sufficient to only extract columns and rows from a table “as is.” However, in the case of invoice data extraction, the semantic understanding of each column is an additional requirement to facilitate the correct extraction of other important invoice fields such as Amounts and Taxes.
For example, the total price listed inside an invoice is often the sum of the amount in the total price column of the line item table. The same reasoning can be applied to the total tax as well. The ability to identify the source information columns for total price or total tax can greatly increase the accuracy of extracting the true invoice total or tax amount. It is this additional requirement on semantic understanding of columns that makes automated, intelligent, and accurate table extraction from electronic invoices hard to achieve.
Creating TableNet is the culmination of Coupa’s long-term investment in machine learning and sophisticated software engineering to solve the problem. This is coupled with our Community Intelligence database with many actual invoices to help train our algorithms.
TableNet is actually a machine-learning system comprised of multiple neural networks working together to:
- generate feature maps from low-level text-rectangles (a fancy way of saying "field names"),
- identify the boundary of the table if there is one in the invoice,
- identify the rows,
- and identify columns and their associated canonical identity (description, quantity, unit price, etc.).
This unique structure for table extraction is inspired by how a human would approach understanding a table from an invoice. It is not done in a single step, but rather it involves a number of logical processes. The first step would be searching where the table is inside the invoice. This search normally involves us identifying two key anchors of a table which are the start (top anchor) and end of the table (bottom anchor). Once a table has been found, we focus our attention only to the table part to understand it further while ignoring other irrelevant information. We understand a table by dissecting its rows and columns. Such a dissection is not only based on the physical characteristics of a table (i.e. its physical line separations and spacing) but also semantics of text-rectangles inside the table. We further group similar texts inside a table together to arrive at a much more precise dissection of rows and columns.
The first few neural network models:
- provide a compact summary of the text-rectangle level information,
- and process this information in a numeric format (feature map) that can be understood by the last two models that we call RowNet and ColumnNet.
RowNet then searches the invoice feature map by means of a running convolutional filter to identify where the top anchor and bottom anchor of the table are. It also identifies the rows inside the table.
Once a table is located, all other text-rectangles are removed from the feature map except for those lying inside the top and bottom anchor. ColumnNet is then used to search and identify columns also by means of a running convolutional filter (much like how we sweep the table using our eyes).
Due to its unique and innovative structure, training of TableNet requires labelled data for all invoice fields. After more than 5 year of systematic and relentless data generation, collection, and cleaning, Coupa has amassed tens of millions of high quality labelled invoice field data. TableNet training being catapulted by these valuable data has resulted in a state-of-art table extraction system. We have tested TableNet against the other PDF reading services from companies like Google, Amazon, and Microsoft.
We’ve found that our specific focus on reading invoices, rather than in reading any document, has led to our success.
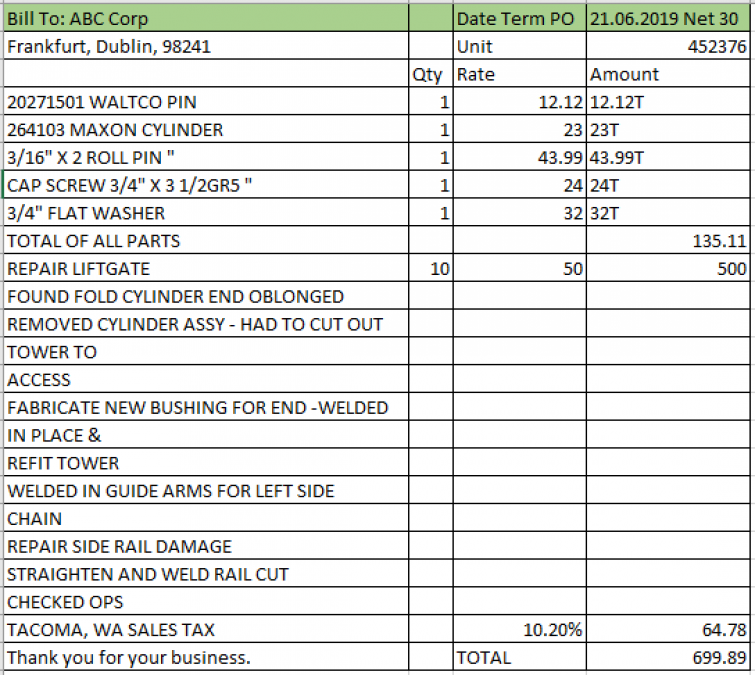
The following example of a table without clear lines shows the difference. This invoice, when looked at by a person, has a clear table. And, with some examination, you can see that the last line item has some freeform text in it.

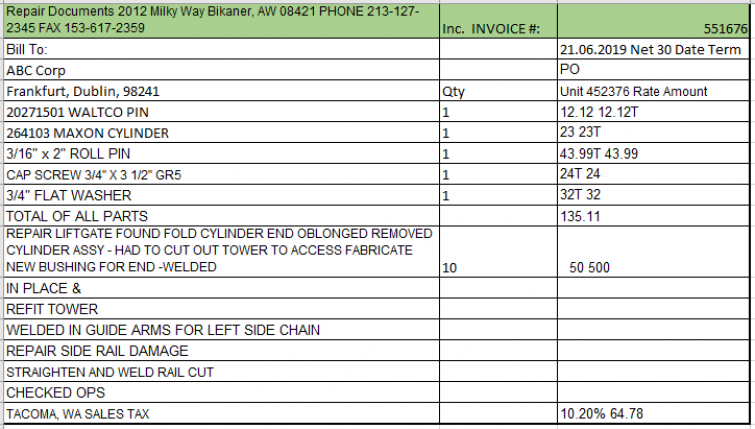
General table reading algorithms can have a hard time with this. Here are two examples from good algorithms for reading general documents. You can see that both of these fail at distilling the information from the above invoice.
TableNet is able to correctly read the table. This is because TableNet is designed and trained to specifically read invoices.
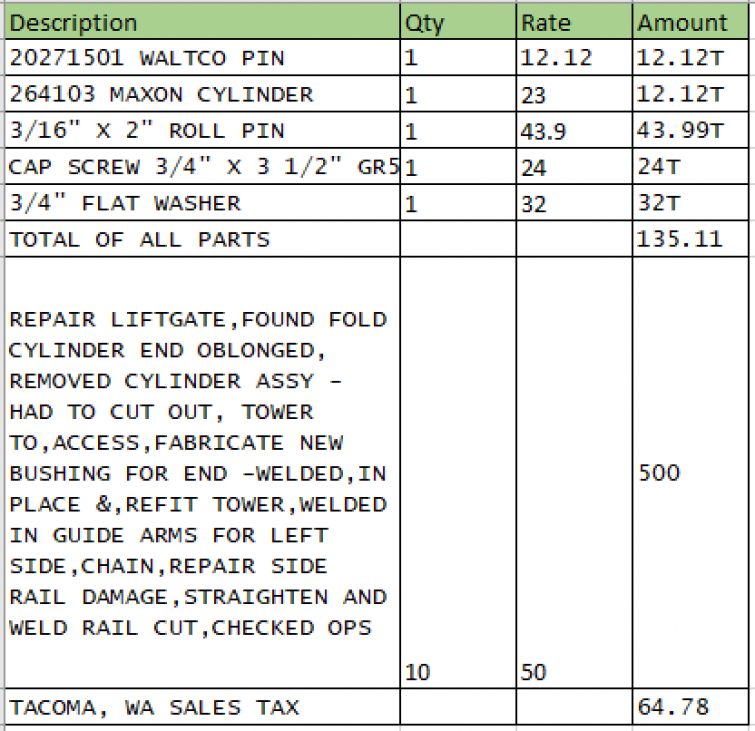
TableNet identifies the table, rows, and columns correctly, and understands the semantic meaning of texts in each column.
And, we are not stopping here. We are continuing to refine the models to read even less structured invoices and to make them faster.
At Coupa, we are committed to the practical use of algorithms to add value to our Business Spend Management (BSM) customers.